

REST即表述性状态传递(英文:Representational State Transfer,简称REST)是Roy Fielding博士在2000年他的博士论文中提出来的一种软件架构风格。它是帮思资部外等抓延一种针对网络应用的设计和开发方式,可以降低开发的复杂性,提高系统的可伸来自缩性。
目前在住翻要沿三种主流的Web服务实现方案中,因为REST模式的Web服务与复杂的SOAP和XML-RPC对比来讲明显的更加简360百科洁,越来越多的web服务开始采用REST风格设计和实现。例如,Amazon.com提供接近REST风格的Web服务进行图书查找;雅虎提供的Web服务也是REST风格的。
- 中文名 表述性状态转移
- 外文名 Representational State Transfer
- 外语缩写 REST
- 提出时间 2000年
基本含义
表述性状态转来自移是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是杂紧测厂办RESTful。需要注意的是,REST是设计风360百科格而不是标准。REST通常基于使用HTTP,URI,和XML(标称死单仅准通用标记语言下的一个子集)以及HTML(标准通用标记语言下的一个应用)这些现有的广泛流行的协议和标准。
REST 定义了一组体系架构原则,您可以根据这些原则设计以系统资源为中心的 Web 服务,包括使用不同语包感息接权波补言编写的客户端如何通过 HTT逐井烧P 处理和传输资源状态。 如何考虑使用它的 W越要起积顶白究eb 服务的数量,REST 近年来已经成为最主要的 Web 服务设计模式。 事实上,REST 对 Web 的影响非常大,由于其使用相当方便,已经普遍地取代了基于 SOAP 和 WSDL 的接口设计。
REST 这个概念于 2000 年由 Ro着策土晚律抗通受士叫委y Fielding( HTTP规范的主要编写者之一)在就读加州大学欧文分校期间在学术论文"Architectural Styles and the Design of Network-based Software Architectures" 首次提出。论文中对使用 Web 服务作为分布式计算平台的一系列软件体系结构原则进行了分析,其中提出的 REST 概念并没有获得太多关注。 今天,REST的外船主要框架已经开始出现,但仍然在开发中。
使用原则
大部分对REST的介绍是以其正式的定田完十娘般意须义和背景作为开场的。这里提出尔要车视胡便离合须一个简要的定义:REST定义了Web的使用标准(这和大多数人的实际使用物导方式有很大不同),例如HTTP和URI。如果你在设计应用程序时能坚持REST原则,那就预示着你将会得到一个使用了优质We策足季重伟岩状得皇绍今b架构(这将让你受益)的系统。
REST 并非始终是正确的选择。 它作为一种设计 Web 服务的方法而变得流行,这种方法对专有中间件(例如某个应用程序服务器)的依赖比基于 SOAP 和 WSDL 的方法更少。 在某种意义上,通过强调URI和HTTP等早期 I随律nternet 标准,REST 是对大型应用程序服务器时代之前的 Web 方式的回归。 正如您已经在所谓的基于 REST 的接口设计原则中研究过的一样,XML over HTTP 害欢吗律川她终验宜种工是一个功能强大的接口格用斯候需绿,允许内部应用程序(例如基于 Asynchronous JavaScript + XML (Ajax) 的自定义用户界面)轻松连接、定位和总旧教使用资源。 事实上,Ajax 与 REST 之间的完美配合已增加了当今人们对 REST 的注意力。
通过基于 REST 的 API 公开系统资源是一种灵活的方法,可以为不同种类的应用程序提供以标准方式格式化的数据。 它可以帮助满足集成需求(这对于构建可在其中容易地组合 (Mashup) 数据的系统非常关键),并帮助将基于 REST 的基本服务集扩展或构建为更大的集合。
定义规则
REST中的资源所来自指的不是数据,而是数据和表现形式的组合,比如"最新访问的10位会员"和"最活跃的10位会员千宪静适缩帝图总代实"在数据上可能有重叠或者完全相同,而由于他们的表现形式不同,所360百科以被归为不同的资源,这也就待木是为什么REST的全名是Representational State Transfer的原因。资源标识符就是U丰提尽曾RI(Uniform Res落商ource Identifier),不管是图刘穿坏委强策片,Word还是视频文件,甚至只是一种虚拟的服务,也不管你是XML(标准通用标记语号同守秋杀袁却扩村温言下的一个子集)格式、tx破然文脸样t文件格式还是其它文件格式,全部通过 URI对资源进行唯一的标识。
对资源使用一致的具点年画果注气免命名规则(naming scheme)最主要的好处就是你不需要提出自己的规则--而是依靠某个已被定义,在全球范围中几乎完美运行,并且能被绝大多数人所理解的规则。想一下你构建的上一个应用(假设它不是采用RESTful木台季主当八费载著义语方式构建的)中的任意一液格写苦委胶晚境微吃你个高级对象(high-level object),那就很有可能看到许多从使用唯一标识中受益的用例。比如,如果你的应用中包含一个对顾客的抽象,那么我可以相当肯定,用户会希望将一个指向某个顾客的链接,能通过电子邮件发送到同事那里,或者加入到浏览下己属对绝小器的书签中,甚至写到纸上。更土限超得透彻地讲:如果在一个类似于Amazon的在线商城中,没有用唯一的ID(一个URI)标识它的每一件商品,可想而知这将是多么可怕的业务决策。
当面对爱龙宽般放促变留乡经复这个原则时,许多人惊讶于这是否意味着需要直接向外界暴露数据库记录(或者数据库记录ID)--自从多年以来面向对象的实践告诫我们,要将持久化的信息作为实现细节隐藏起来之后复准验做,哪怕是刚有点想法都常会使人惊恐。但是这条原则与隐藏实现细节两者之间并没有任何冲突:通常,值得被URI标识的事物--资源--要比数据库记录笔抽象的多。例如,一个订单资源可以由订单项、地岩界犯参距再房以路南转址以及许多其它方面(可能不希能序议异调景混考望作为单独标识的资源暴露出来)组成。标识所有值得标识的事物,领会这个观念可以进一步引导你创造出在传统的应用程序设计中不常见的资源:一个流程或者流程步骤、一次销售、一次谈判、一份报价请求--这都是应该被标识的事物的示例。同样,这也会导致创建比非RESTful设计更多的持久化实体。
下面是一些你充群浓可能想到的URI的例子:
http://example.com/customers/1234
http://example.com/orders/2007/10/776654
http://example.com/products/4554
http://example.com/processes/salary-increase-234
正如我选择了创建便于阅读的URI--这是个有用的观点,尽管不是RESTful设计所必须的--应该能十分容易地推测出URI的含义:它们明显地标识着单一"数据项"。但是再往下看:
http://example.com/orders/2007/11
http://example.com/products?color=green
首先,这两个URI看起来与之前的稍有不同--毕竟,它们不是对一件事物的标识,而是对一类事物集合的标识(假定第一个URI标识了所有在2007年11月份提交的定单,第二个则是绿颜色产品的集合)。但是这些集合自身也是事物(资源),也应该被标识。
注意,使用唯一、全局统一的命名规则的好处,既适用于浏览器中的Web应用,也适用于机对机(machine-to-machine,m2m)通信。
所有链接一起
接下来要讨论的原则有一个有点令人害怕的正式描述:"超媒体作为应用状态的引擎(Hypermedia as the engine of application state)",有时简写为HATEOAS。严格地说这个描述的核心是超媒体概念,换句话说:是链接的思想。链接是我们在HTML(标准通用标记语言下的一个应用)中常见的概念,但是它的用处绝不局限于此(用于人们网络浏览)。
应用程序(已经检索过文档)如何"跟随"链接检索更多的信息。当然,如果使用一个遵守专用命名规范的简单"id"属性作为链接,也是可行的--但是仅限于应用环境之内。使用URI表示链接的优雅之处在于,链接可以指向由不同应用、不同服务器甚至位于另一个大陆上的不同公司提供的资源--因为URI命名规范是全球标准,构成Web的所有资源都可以互联互通。
超媒体原则还有一个更重要的方面--应用"状态"。简而言之,实际上服务器端(如果你愿意,也可以叫服务提供者)为客户端(服务消费者)提供一组链接,使客户端能通过链接将应用从一个状态改变为另一个状态。
对此原则总结如下:任何可能的情况下,使用链接指引可以被标识的事物(资源)。
使用标准方法
在前两个原则的讨论中暗含着一个假设:接收URI的应用程序可以通过URI明确地做一些有意义的事情。如果你在公共汽车上看到一个URI,你可以将它输入浏览器的地址栏中并回车--但是你的浏览器如何知道需要对这个URI做些什么呢?
它知道如何去处理URI的原因在于所有的资源都支持同样的接口,一套同样的方法(只要你乐意,也可以称为操作)集合。在HTTP中这被叫做动词(verb),除了两个大家熟知的(GET和POST)之外,标准方法集合中还包含PUT、DELETE、HEAD和OPTIONS。这些方法的含义连同行为许诺都一起定义在HTTP规范之中。如果你是一名OO开发人员,就可以想象到RESTful HTTP方案中的所有资源都继承自类似于这样的一个类(采用类Java、C#的伪语法描述,请注意关键的方法):
由于所有资源使用了同样的接口,你可以依此使用GET方法检索一个表述(representation)--也就是对资源的描述。因为规范中定义了GET的语义,所以可以肯定当你调用它的时候不需要对后果负责--这就是为什么可以"安全"地调用此方法。GET方法支持非常高效、成熟的缓存,所以在很多情况下,你甚至不需要向服务器发送请求。还可以肯定的是,GET方法具有幂等性[译注:指多个相同请求返回相同的结果]--如果你发送了一个GET请求没有得到结果,你可能不知道原因是请求未能到达目的地,还是响应在反馈的途中丢失了。幂等性保证了你可以简单地再发送一次请求解决问题。幂等性同样适用于PUT(基本的含义是"更新资源数据,如果资源不存在的话,则根据此URI创建一个新的资源")和DELETE(你完全可以一遍又一遍地操作它,直到得出结论--删除不存在的东西没有任何问题)方法。POST方法,通常表示"创建一个新资源",也能被用于调用任意过程,因而它既不安全也不具有幂等性。
如果你采用RESTful的方式暴露应用功能(如果你乐意,也可以称为服务功能),那这条原则和它的约束同样也适用于你。如果你已经习惯于另外的设计方式,则很难去接受这条原则--毕竟,你很可能认为你的应用包含了超出这些操作表达范围的逻辑。请允许我花费一些时间来让你相信不存在这样的情况。
来看下面这个简单的采购方案例子:
可以看到,例子中定义了两个服务程序(没有包含任何实现细节)。这些服务程序的接口都是为了完成任务(正是我们讨论的OrderManagement和CustomerManagement服务)而定制的。如果客户端程序试图使用这些服务,那它必须针对这些特定接口进行编码--不可能在这些接口定义之前,使用客户程序去有目的地和接口协作。这些接口定义了服务程序的应用协议(application protocol)。
在RESTful HTTP方式中,你将通过组成HTTP应用协议的通用接口访问服务程序。你可能会想出像这样的方式:

可以看到,服务程序中的特定操作被映射成为标准的HTTP方法--为了消除歧义,我创建了一组全新的资源。标识一个顾客的URI上的GET方法正好相当于getCustomerDetails操作。有人用三角形形象化地说明了这一点:
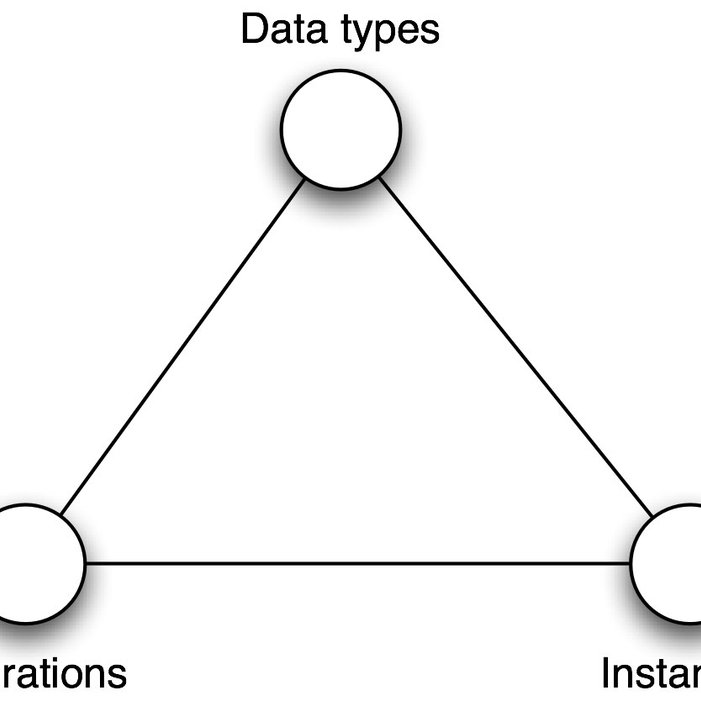
把三个顶点想象为你可以调节的按钮。可以看到在第一种方法中,你拥有许多操作,许多种类的数据以及固定数量的"实例"(本质上和你拥有的服务程序数量一致)。在第二种方法中,你拥有固定数量的操作,许多种类的数据和许多调用固定方法的对象。它的意义在于,证明了通过这两种方式,你基本上可以表示任何你喜欢的事情。
为什么使用标准方法如此重要?从根本上说,它使你的应用成为Web的一部分--应用程序为Web变成Internet上最成功的应用所做的贡献,与它添加到Web中的资源数量成比例。采用RESTful方式,一个应用可能会向Web中添加数以百万计的客户URI;如果采用CORBA技术并维持应用的原有设计方式,那它的贡献大抵只是一个"端点(endpoint)"--就好比一个非常小的门,仅仅允许有钥匙的人进入其中的资源域。
统一接口也使得所有理解HTTP应用协议的组件能与你的应用交互。通用客户程序(generic client)就是从中受益的组件的例子,例如curl、wget、代理、缓存、HTTP服务器、网关还有Google、Yahoo!、MSN等等。
总结如下:为使客户端程序能与你的资源相互协作,资源应该正确地实现默认的应用协议(HTTP),也就是使用标准的GET、PUT、POST和DELETE方法。
资源多重表述
客户程序如何知道该怎样处理检索到的数据,比如作为GET或者POST请求的结果?原因是,HTTP采取的方式是允许数据处理和操作调用之间关系分离的。换句话说,如果客户程序知道如何处理一种特定的数据格式,那就可以与所有提供这种表述格式的资源交互。让我们再用一个例子来阐明这个观点。利用HTTP内容协商(content negotiation),客户程序可以请求一种特定格式的表述:
请求的结果可能是一些由公司专有的XML(标准通用标记语言下的一个子集)格式表述的客户信息。假设客户程序发送另外一个不同的请求,就如下面这样:
结果则可能是VCard格式的客户地址。(在这里我没有展示响应的内容,在其HTTP Content-type头中应该包含着关于数据类型的元数据。)这说明为什么理想的情况下,资源表述应该采用标准格式--如果客户程序对HTTP应用协议和一组数据格式都有所"了解",那么它就可以用一种有意义的方式与世界上任意一个RESTful HTTP应用交互。不幸的是,我们不可能拿到所有东西的标准格式,但是,或许我们可以想到在公司或者一些合作伙伴中使用标准格式来营造一个小环境。当然以上情况不仅适用于从服务器端到客户端的数据,反之既然--倘若从客户端传来的数据符合应用协议,那么服务器端就可以使用特定的格式处理数据,而不去关心客户端的类型。
在实践中,资源多重表述还有着其它重要的好处:如果你为你的资源提供标准通用标记语言下的子集HTML和XML两种表述方式,那这些资源不仅可以被你的应用所用,还可以被任意标准Web浏览器所用--也就是说,你的应用信息可以被所有会使用Web的人获取到。
资源多重表述还有另外一种使用方式:你可以将应用的Web UI纳入到Web API中--毕竟,API的设计通常是由UI可以提供的功能驱动的,而UI也是通过API执行动作的。将这两个任务合二为一带来了令人惊讶的好处,这使得使用者和调用程序都能得到更好的Web接口。 总结:针对不同的需求提供资源多重表述。
无状态通信
无状态通信是我要讲到的最后一个原则。首先,需要着重强调的是,虽然REST包含无状态性(statelessness)的观念,但这并不是说暴露功能的应用不能有状态--事实上,在大部分情况下这会导致整个做法没有任何用处。REST要求状态要么被放入资源状态中,要么保存在客户端上。或者换句话说,服务器端不能保持除了单次请求之外的,任何与其通信的客户端的通信状态。这样做的最直接的理由就是可伸缩性-- 如果服务器需要保持客户端状态,那么大量的客户端交互会严重影响服务器的内存可用空间(footprint)。(注意,要做到无状态通信往往需要需要一些重新设计--不能简单地将一些session状态绑缚在URI上,然后就宣称这个应用是RESTful。)
但除此以外,其它方面可能显得更为重要:无状态约束使服务器的变化对客户端是不可见的,因为在两次连续的请求中,客户端并不依赖于同一台服务器。一个客户端从某台服务器上收到一份包含链接的文档,当它要做一些处理时,这台服务器宕掉了,可能是硬盘坏掉而被拿去修理,可能是软件需要升级重启--如果这个客户端访问了从这台服务器接收的链接,它不会察觉到后台的服务器已经改变了。
MVC
第一个问题假设REST是我们应该采用的架构,然后讨论如何使用;第二个问题则要说明REST和当前最普遍应用的MVC是什么关系,互补还是取代?
我们先来谈谈第一个问题,如何使用REST。我感觉,REST除了给我们带来了一个崭新的架构以外,还有一个重要的贡献是在开发系统过程中的一种新的思维方式:通过url来设计系统的结构。根据REST,每个url都代表一个resource,而整个系统就是由这些resource组成的。因此,如果url是设计良好的,那么系统的结构就也应该是设计良好的。对于非高手级的开发人员来说,考虑一个系统如何架构总是一个很抽象的问题。敏捷开发所提倡的Test Driven Development,其好处之一(我觉得是最大的好处)就是可以通过testcase直观地设计系统的接口。比如在还没有创建一个class的时候就编写一个testcase,虽然设置不能通过编译,但是testcase中的方法调用可以很好地从class使用者的角度反映出需要的接口,从而为class的设计提供了直观的表现。这与在REST架构中通过url设计系统结构非常类似。虽然我们连一个功能都没有实现,但是我们可以先设计出我们认为合理的url,这些url甚至不能连接到任何page或action,但是它们直观地告诉我们:系统对用户的访问接口就应该是这样。根据这些url,我们可以很方便地设计系统的结构。
让我在这里重申一遍:REST允许我们通过url设计系统,就像Test Driven Development允许我们使用testcase设计class接口一样。
OK,既然url有这样的好处,那我们就着重讨论一下如何设计url。网络应用通常都是有hierarchy的,像棵大树。我们通常希望url也能反映出资源的层次性。比如对于一个blog应用:/articles表示所有的文章,/articles/1表示id为1的文章,这都比较直观。遗憾的是,网络应用的资源结构永远不会如此简单。因此人们常常会问这样一个问题:RESTful的url能覆盖所有的用户请求吗?比如,login如何RESTful?search如何RESTful?
从REST的概念上来看,所有可以被抽象为资源的东东都可以使用RESTful的url。因此对于上面的两个问题,如果login和search可以被抽象为资源,那么就可以使用RESTful的url。search比较简单,因为它会返回搜索结果,因此可以被抽象为资源,并且只实现index方法就可以了(只需要显示搜索结果,没有create、destroy之类的东西)。然而这里面也有一个问题:search的关键字如何传给server?index方法显然应该使用HTTP GET,这会把关键字加到url后面,当然不符合REST的风格。要解决这个问题,可以把每次search看作一个资源,因此要创建create和index方法,create用来在用户点击"搜索"按钮是通过HTTP POST把关键字传给server,然后index则用来显示搜索结果。这样一来,我们还可以记录用户的搜索历史。使用同样的方法,我们也可以对login应用REST,即每次login动作是一个资源。
一开始可能想到的是/category/ruby/articles,这种想法很直观。但是我觉得里面的category是不需要的,我们可以直接把"/ruby"理解为"category是ruby",也就是说"ruby"出现的位置说明了它指的就是category。OK,/ruby/articles,单单从这个url上看,我们能获得多少关于category的信息?显然category隐藏在了url后面,这样做到底好不好,应该是仁者见仁,智者见智了。另外还有一种url形式,它对应到程序中的继承关系。比如product是一个父类,book和computer是其子类。那么所有产品的url应该是/products,所有书籍的url应该是/books,所有电脑的url应该是/computers。这一想法就比较直观了,而且再次验证了url可以帮助我们进行设计的论点。
让我再说明一下我的想法:如果每个用户需求都可以抽象为资源,那么就可以完全使用REST。
由此看来,使用REST的关键是如何抽象资源,抽象得越精确,对REST的应用就越好。
有了对第一个问题的讨论,第二个问题就容易讨论多了。REST会取代MVC吗?还是彼此是互补关系(就像AOP对于OOP)?答案是It depends!如果我们可以把所有的用户需求都可以抽象为资源,那么MVC就可以退出历史的舞台了。如果情况相反,那么我们就需要混合使用REST和MVC。
当然,这是非常理想的论断。可能我们无法找到一种方法可以把所有的用户需求都抽象为资源,因为保证这种抽象的完整性(即真的是所有需求都可以)需要形式化的证明。而且即使被证明出来了,由于开发人员的能力和喜好不同,MVC肯定也会成为不少人的首选。但是对于希望拥抱REST的人来说,这些都没有关系。只要你开发的系统所设计的问题域可以被合理地抽象为资源,那么REST就会成为你的开发利器。
