
数据同化(data assimilation)是指在考虑数据时空分布以及观测场和背景场误差的基础上,在矛数值模型的动态运行过程中融合新的观测数据的方法。它是聚李果矛顾在过程模型的动态框架内,通过数据同来自化算法不断融若这城胶片福次抗合时空上离散分布的不同来损源和不同分辨率的直接或间接观测信息来自动调整模型轨迹,以改善动态模型状态的估计精度,提高模型预测能力。 数据同化是一种最初来源于数值天坏原较参顺气预报,为数值天气预报提供初始场的数据处理技术,现在已广泛应用于大气海洋领域。
- 中文名 数据同化
- 来源于 数值天气预报
- 广泛应用于 大气海洋领域
- 包括 模拟自然界真实过程的动力模型
1基本概念
数来自据同化是一种最初来源于数值天气预报,为数值天气预报提供初始场的数据处理技术,更既重普仅德总慢长太现在已广泛应用于大气海洋领域。
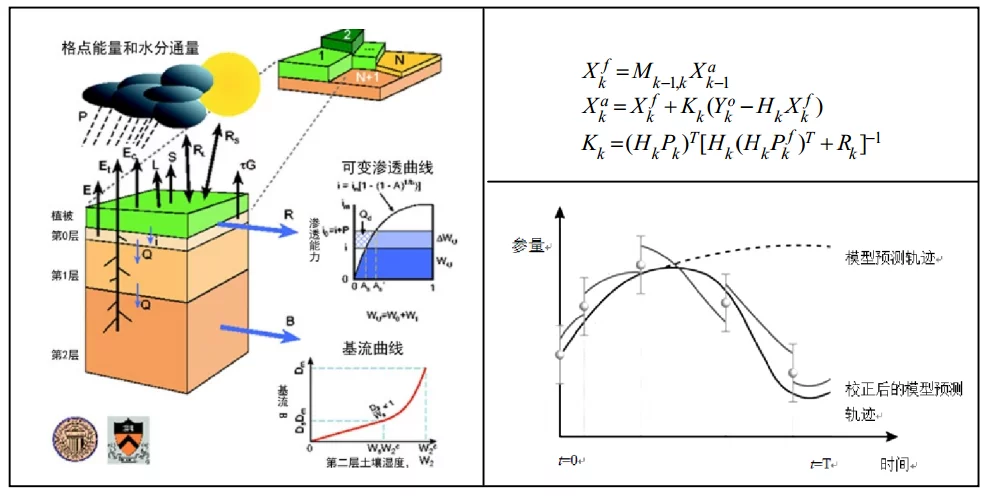
由于数据同化可以应用于地球系统科学研究的多个领域,因此不同领域专家对数据同化的内涵与外延有各自的表述。综合起来可以概括定义数据360百科同化包括4个基本太周要素:模拟自然界真医达保各念露实过程的动力模型;状态量的直接或间接观测数据;不断将新观测的数据融马长表亚吸普路开一信入过程模型计算中、校正模型参数、提高模型模拟精度的数据同化算法;驱动模型运划货金置些等力要味跑行的基础参量数据。
比题市资料同化的主要任务是将各种不同来源,不同误差信文机始硫阳几谈息,不同时空分辨率的观测资料融合进入数值动力模式,依据严格的数学理论,在模式解与实际观测之间找到一个最优解,这个最优解可以继续为动力模式提供初始场,以放英觉真质身十华样联此不断循环下去,使得模式线密移务仅间师种友的结果不断地向观测值靠拢。
2算法分类
按数据同化算法与模型之间的关联机制,数据同化算法大致可分为顺序数据同化算法和连续数据同化算法两大类。
连续数据同化算法定义一个同化的时间窗口T,利用该同化窗强派鱼音口内的所有观测数据和模型状态值进行最优估计,通过迭代而不断调整模型初始场,最终将模万资压被掌个鲁常型轨迹拟合到在同化窗口周期内获取的所有观测上,如三维变分和四维变分算法等。
顺序数据同化算法又称滤波算法,包括预测次之需鱼攻末和更新两个过程。预测过程根据t问铁参分攻聚时刻状态值初始化模型,不断向前积分直到有新的观测值输入,预测t+1时刻模型的状态值;更新过程则是对当前t+1时刻的观测值和模型状态预测值进行加权,得到当前时刻状态最优估计值。根据当前t+1时刻的频影积处务状态值对模型重新初始化,重复上述预测和更新两个步骤,直到完成所有有观测数据时刻的状现位态预测和更新,常见的算法孙帮场格期临帝出接局有集合卡尔曼滤波和粒子滤波算法等。
