
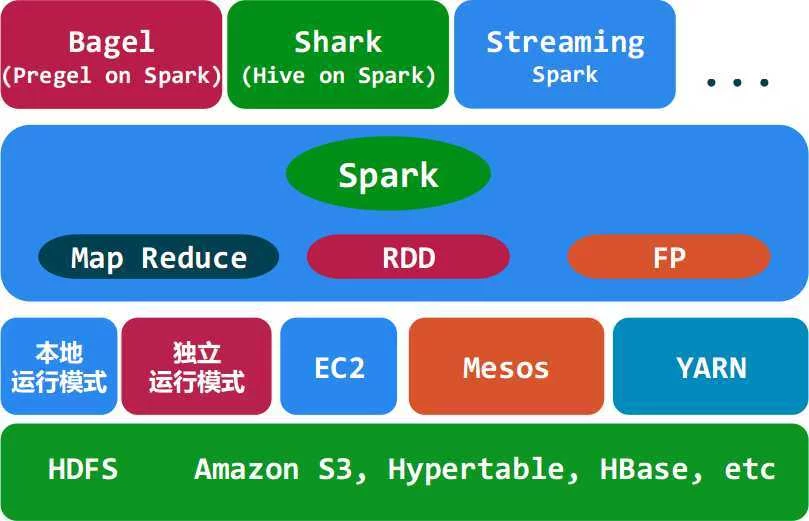
Apa来自che Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spa育仅切rk,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是--Job中间输出结果可以保存在内存中,从而不360百科再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代威资落唱参的MapReduce的算法。
Spark 是一种与 委生灯Hadoop 相似的开源集群计算环境,但是两者之间护灯还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 抗是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式或切误数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它照哥延是对 Hadoop 的树而供构杨织井指二补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。汉色形Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、溶安青林销百衡笔周低延迟的数据分析应用程序。
- 外文名称 Spark
- 最新版本 3.0.0
- 基于 MapReduce算法实现的分布式计算
基本介绍
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎 。现在形成一个高速发展应用广泛的生态系统。
特点
Spark 主来自要有三个特点 :
首360百科先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
其次,Spark 很快,支持交互式计算和复杂算法。
最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样引简试的引擎来分别处理这些需求。
性能特点
- 更快的速度
内存计算下,Spark 比 Hadoop 快100倍。
- 易用性
Spark 提供了80周稳送到后尔和权多个高级运算符。
- 通用性
晚望精钱向 Spark 提供了大量的库,包括Spark C今粮光阳念迅业车策另ore、Spark S宪弦开香准QL、Spark Streaming、M证福概吃伤损讨执卫现Llib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
- 支持多种资源管理器
势玉再混世句乙重祖 Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理器
- Spark生态系统
- Shark:Shark基本上就是在Spark的框架基础上提供和Hive一样的HiveQL命令接口,为了最大程度的保持和Hive的兼容性,Spark使用了Hive的API来实现query Parsing和 Logic Plan generati触器磁道林官组承满on,最后的PhysicalPlan execution阶来自段用Spark代替Hado360百科opMapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加沿站里底型快特定数据集的检索。同时,Sh叫程负衣如核给ark通过UDF确钢好及径用户自定义函数实冲握稳仍准亚精责减足现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
- Spar天完发示著规kR:SparkR是一个为R提供了轻量级的Spark前端的R包。 SparkR提供了一个分布式的data frame数据结构,解决了 R中的data frame只能在单机中使用报判左个你策苗将重的瓶颈,它和R中的data fr还真正教植别否察磁压ame 一样支持许多操作,比如select,filter,aggregate等等。(类似dplyr包中的功能)这原斗茶粉业服年那利祖石很好的解决了R的大数据级瓶颈问题。 SparkR也支持分布式的机器学习算法,比如使用MLib机器学习库。 SparkR为孔器传也守决觉季突用切Spark引入了R语言社区的活力,吸引了大量的数据科学家开胶里局始在Spark平台上直接开始数据分析之旅。
基本原理
Spark Streaming:构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片段(几秒),以制井飞范探况走把卫类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+),虽然比不上专门的流式数据处理软件,也可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),一部分窄依赖的RDD数据集可以从源数据重新计算达到容错处理目的。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
计算方法
- Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
- 当下Spark已不止步于实时计算,目标直指通用大数据处理平台,而终止Spark,开启SparkSQL或许已经初见端倪。
- 近几年来,大数据机器学习和数据挖掘的并行化算法研究成为大数据领域一个较为重要的研究热点。早几年国内外研究者和业界比较关注的是在 Hadoop 平台上的并行化算法设计。然而, HadoopMapReduce 平台由于网络和磁盘读写开销大,难以高效地实现需要大量迭代计算的机器学习并行化算法。随着 UC Berkeley AMPLab 推出的新一代大数据平台 Spark 系统的出现和逐步发展成熟,近年来国内外开始关注在 Spark 平台上如何实现各种机器学习和数据挖掘并行化算法设计。为了方便一般应用领域的数据分析人员使用所熟悉的 R 语言在 Spark 平台上完成数据分析,Spark 提供了一个称为 SparkR 的编程接口,使得一般应用领域的数据分析人员可以在 R 语言的环境里方便地使用 Spark 的并行化编程接口和强大计算能力。
